
There are a million of reasons why you might not want to visit a particular website. Maybe it’s your competitor and you do not want him/her to notice you are ‘watching’ them. Or maybe you’re in an investigation where you do not want your target to be alarmed by any visits. So how can you figure out what is on a website, without paying a visit? Well, we’ve got many options lined up for you:
Online Archives
First, check to see if a website might be archived online. There are two mayor archives you could pay a visit.
Archive.org (The Wayback Machine)
Archive.org is probably the most famous and the biggest one out there. Using the Wayback Machine is quite easy. Just visit https://web.archive.org and type in the domain of choice into the search bar. If the Wayback Machine holds any archived versions, you’ll be able to see the results immediately. This way you’re be able to browse around the page for as long as you’d like without alarming the website owner.
Is your website not in the Wayback Machine? You could send a request to let them archive it. But be aware; the owner of the website might notice that the crawler of the Wayback Machine is visiting the website! Go to https://web.archive.org/ and use the search bar on the right, with the title ‘Save Page Now’, and fill in the address of your choice. Do remember that there is a risk of compromise here.
Archive.ph (Archive.today)
Their top level domain changes sometimes, but either archive.ph or archive.today will take you where you want to be; an online archive of websites. Don’t let your responsiveness lead you to their top search bar, but scroll down just a little to the bottom search bar (dark blue) with the title ‘I want to search the archive for saved snapshots’. If you use the top (red) search bar with the title ‘My URL is live and I want to archive its content’, you’ll request that they archive your website of choice and this, like archive.org, might alarm the owner of the site. Archive.ph might be a little bit smaller than the Wayback Machine, but there can still be some gems in there! So keep diggin’ 😉
Domaintools Whois
Some of you might be familiar with the website domaintools.com where there are some pretty nice products available for when researching domains. One of the things they offer is a free domain lookup, a ‘whois’. At https://whois.domaintools.com/ you can type in any domain name to see to whom it belongs. Although this might be interesting information, we want to see what a website might look like. Luckily they offer a tiny screenshot of the particular domain. But of course we want a larger view and that is possible! Just follow the following steps:
- Let’s look at Google.com for example
- In the box on the right, right-click with your mouse on the image of the historical screenshot
- Select the option ‘Inspect’
- It will highlight a URL starting with ‘https://screenshots.ar.domaintools’
- When hovering over the URL, a box pops up. The full URL length is shown under ‘Current source’.
- Click on the URL
- Now you’ll be able to view an enlarged version of the screenshot. Like the one here.
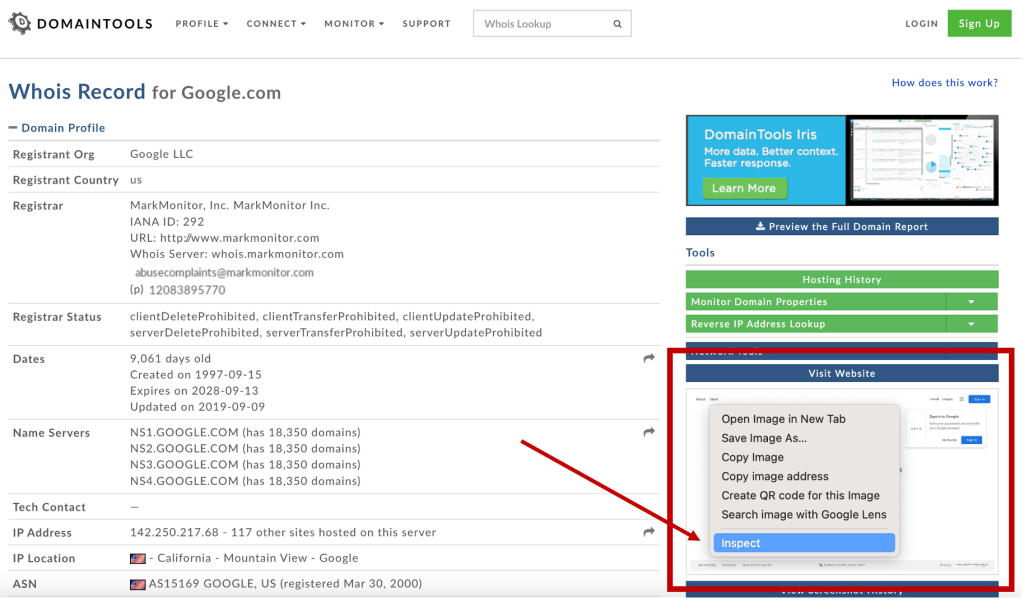
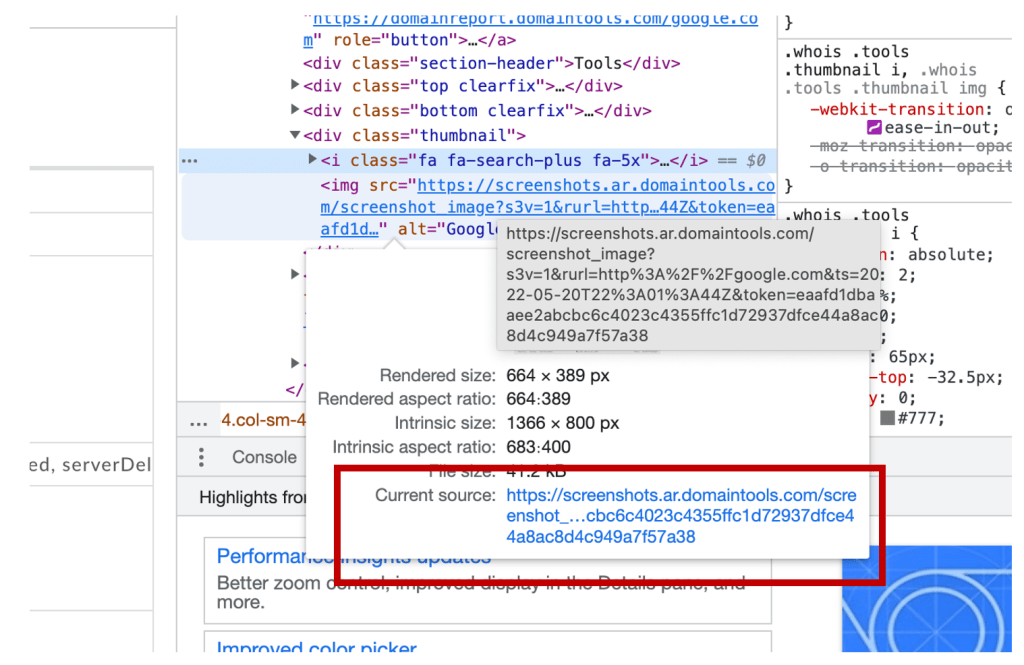
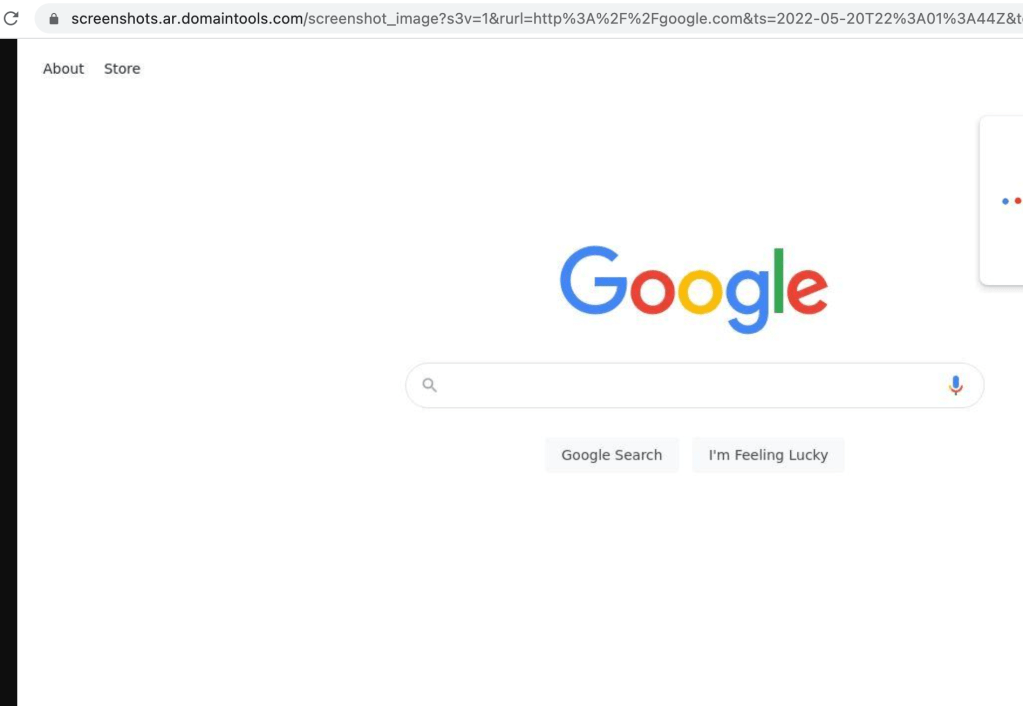
Sometimes there are more screenshots available but unfortunately those are only accessible for those with a paid account. Never the less a great option that often gets forgotten.
Search Engine Cache
Google and Bing both offer cached versions of results they’ve indexed. Not all results have a cached versions, but most of them do.
Google Cache
The most popular search engine, Google, lets you see a cached version of a result. This is a great way to get a sneak peak of what a result might hold. The cached version can be found under the three-dot-menu at the end of a result. Once clicked on the menu, you’ll see the button ‘Cached’ appear. If you don’t see this button, Google has no cached version unfortunately.
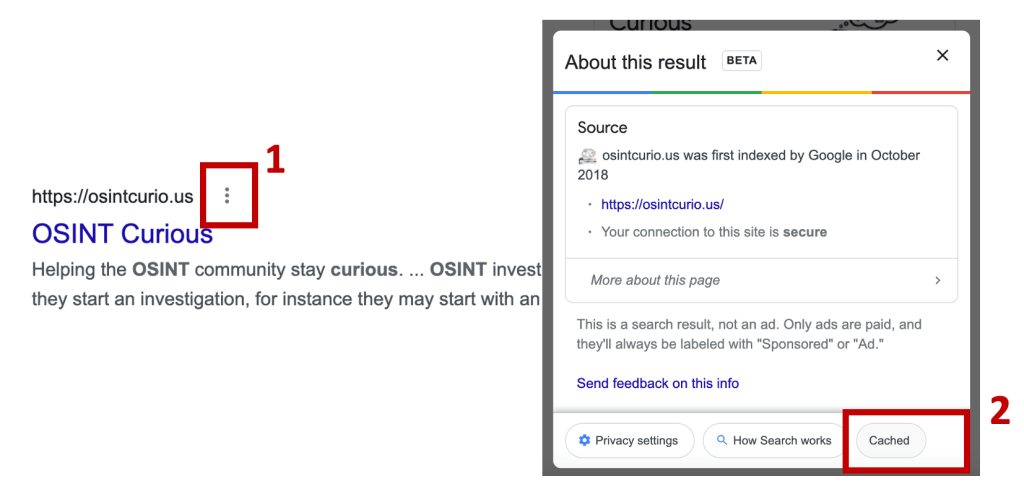
Be aware! Visiting a cached version of a website doesn’t come without consequences! There is still live data being requested from the website you want to view so the owner can still be alarmed! There is a way to prevent this:
- Click on the three-dot-menu to open the cache
- Right-click on the button ‘Cached’
- Select the option to ‘Copy Link Address’
- Now open a new tab in your browser and paste the just copied address in the address bar
- Before you press Enter, at the end of the URL write &strip=1 This will make sure the live data will no longer be requested from the website.
- Now it’s safe to press Enter!
You’ll see that the page will be less visually attractive, but at least you know you’re safe 🙂
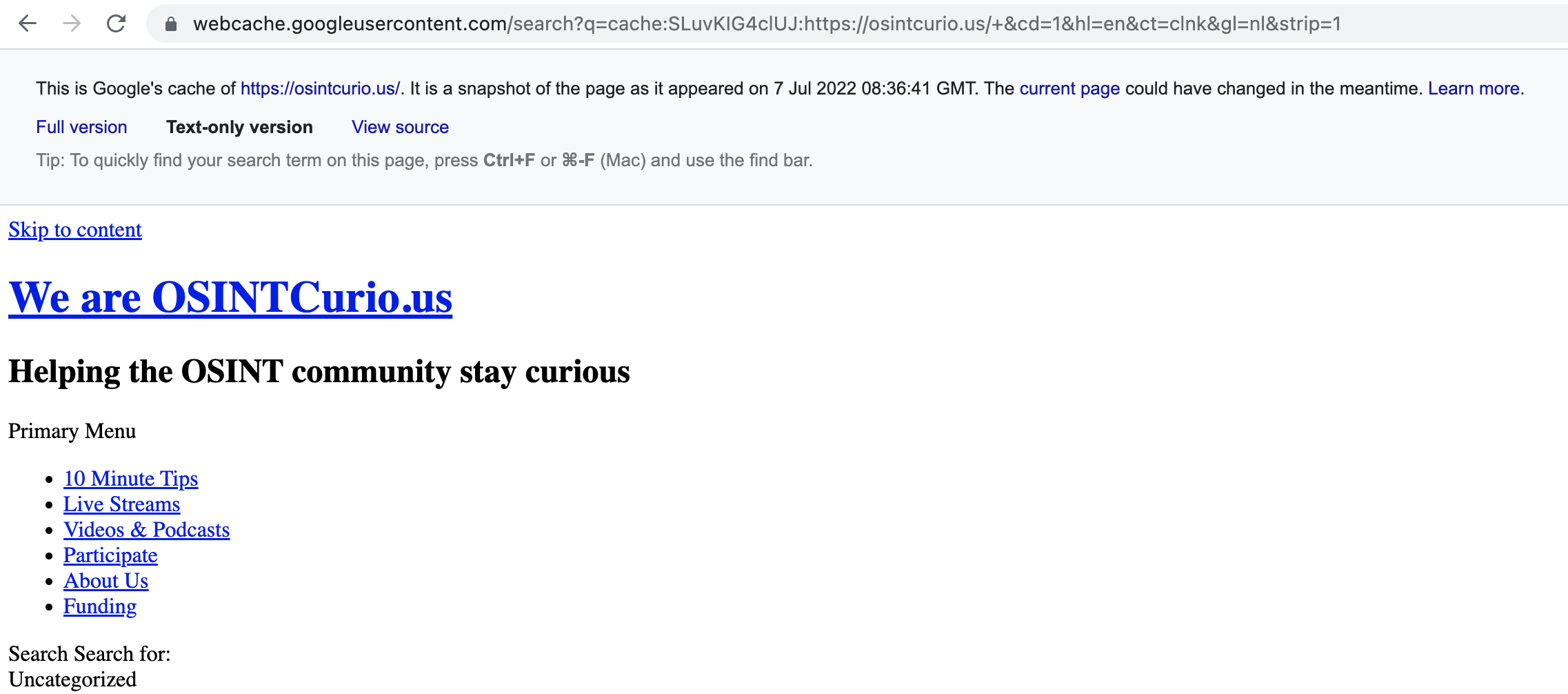
Left: normal cached version
Right: cached version without requesting any live data
Bing Cache
Bing also offers a cache version of most of the results they index. You can find Bings cache when clicking on the green triangle at the end of the URL result. Once clicked, a box with the text ‘Cached’ will appear. No box? No cache unfortunately.
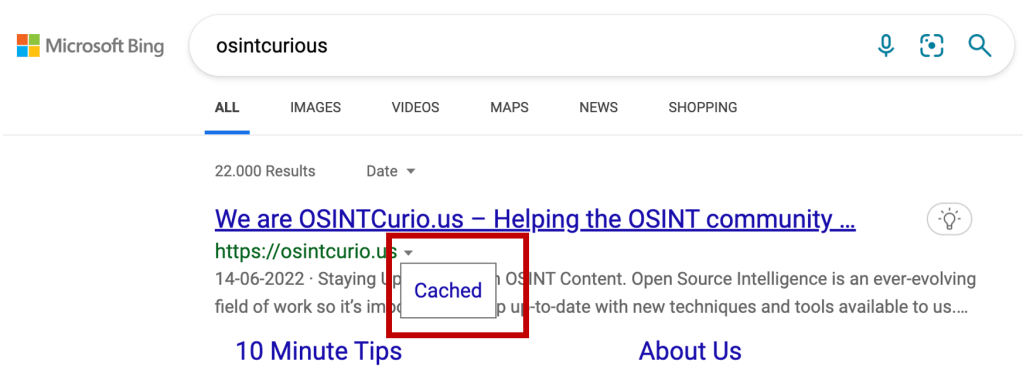
When requesting information from Bings cache, do keep in mind that live data is still being requested. Although for Google Cache we found a workaround, we haven’t found this for Bing Cache yet. If you’re reading this and you might have the answer to this problem, we’d love to hear from you in the comments below or contact us via our social channels!
Third Party Aggregators
Another option is to ask a third party site like the sites mentioned below to visit the target website on your behalf. This continues to maintain your privacy and security while still allowing you to see the live content on the target site.
The three free web applications that we use for this are:
The sites above gather data from the live target site, pull related content from their proprietary databases of historic data, and perform some analyses on that content. Some examples of what they do are:
- Take screenshots of the live sites
- Analyze the HTML and JavaScript to determine if there is malicious content being served
- Show you the resources that make up the site and what other websites the target site pulls data from or links to
- Analyzes analytics codes to help you find other sites that may be related to your target
We suggest that you take a target URL and run it through each of the above sites and compare the extracted and analyzed data.
Screenshots
The last two options might be a little more risky. When downloading a complete website or when asking a third party to make a screenshot for you, this might alarm the owner of the website because live data has to be requested. So do keep this in mind; making screenshots and downloading can be a risk of compromise of your identity and/or of your investigation.
If you’re willing to take the risk, one option would be to ask a third party website to take a screenshot for you. There are many websites out there that can help you do just that. One of them is site-shot.com. Simply fill in the URL at the top search bar and adjust any of the settings on the left if you wish and press the red ‘shot’ button when done.
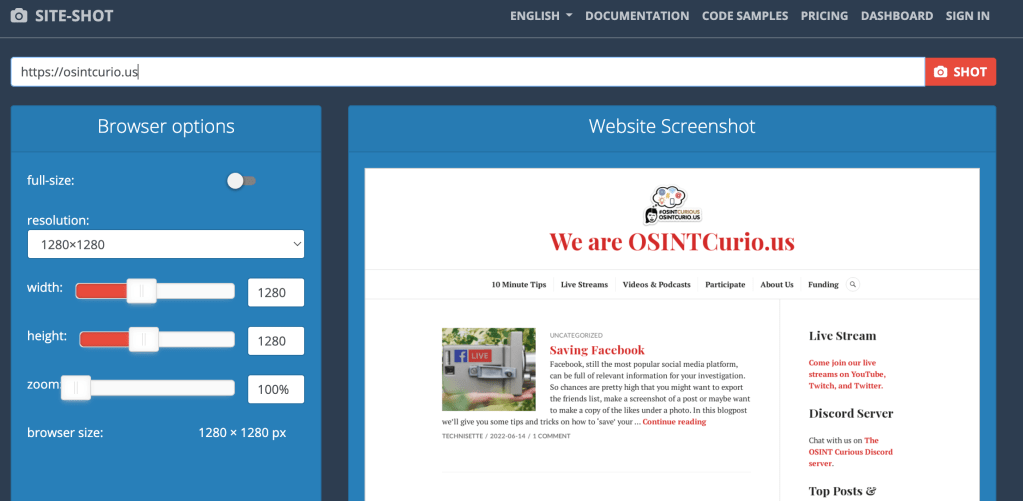
Other options of website that offer similar services are screenshotmachine.com (also offers to save as a PDF) or fullpagescreencapture.com. If you have any other suggestions, we’re happy to hear from you in our comments or on our social channels!
Command Line Tools
There are a few command line tools that are very powerful for gathering website content. It’s important to be aware that although these three tools might not run in a browser, they still access the target website directly from your computer and so reveal your IP address and some system information.
However since these tools will run on any Linux system, you can install and run them on a server anywhere in the world. This means you can grab the content of entire websites without using a browser and without using your own device to do so. Let’s have a look at the tools:
Wget – is a tool that visits a website and can download files of any type, include the html and css files that form the basis of the site. It can go many levels deep into a website and can be customised to ignore robots.txt files and other settings that can limit other tools.
Httrack – this is a website archiving tool that will automatically scrape the content of an entire site so that you keep your own offline version of it. This is useful when you want to preserve content that might be taken offline. Httrack is a command line tool but there is also a GUI version if you’d prefer to run it on your desktop. Although running it from your own machine will leave your footprint on the subject site.
EyeWitness – was originally designed as a security tool but it’s ideal for OSINT too. It runs from the command line but will visit any URL you provide and capture a screenshot of the webpage as well as information about the server. You can see how it works in this tutorial video we made previously.
Conclusions
The above sites and techniques are just a few of the methods of using third party tools to visit those sensitive sites that you cannot or do not wish to directly access during your investigation. Please use the comments section to let us know if there are free tools or sites you use for these purposes that we might not know of.