
When doing OSINT research, it might occur that the page you’re interested in, isn’t available anymore. Or that you get the request to research something that has already been deleted and no screenshots were taken. If you struggle where to begin or what tools might be helpful to use, here are some of our suggestions to help you start your research.
The website I’m researching has been deleted
Let’s say you’re investigating a website. You’ve got the domain name, but the content is unavailable or deleted.
Domain name registration
Checking the domain registration might help you out a little. If you can’t find any useful information, maybe our blog on how to research domain names after the GDPR will help you out. There are a lot of websites which can help you, many of them named in our blog.
Cache
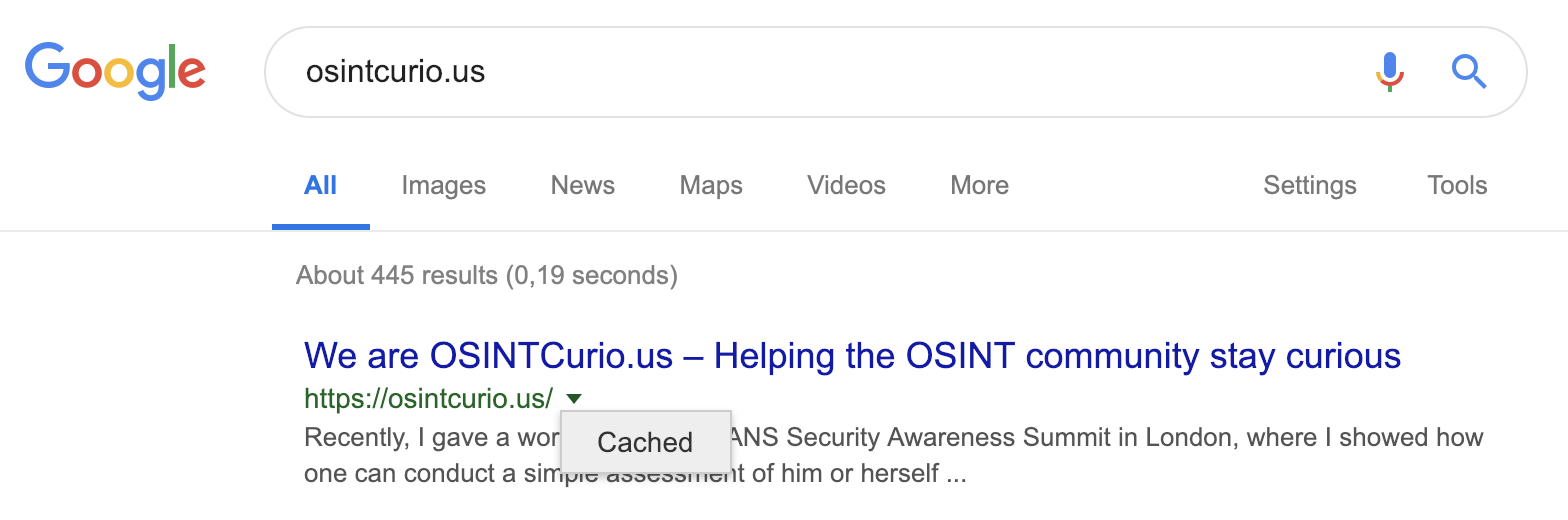
If you’re using Google a lot, you might have noticed this handy trick:
- Right next to the green URL there is this little triangle icon
- If you click on the triangle, it gives you the option to view the cached version of the URL or it gives you a similar version (which not always works out great)
- If you select the cached version, you will find an archived version of the website of interest
For those of you who use Bing and Yandex; they offer you the same thing. There is also a triangle icon which gives you the option to select the cached version of the website.
OPSEC Warning about Google Cache
One important thing to note about Google Cache content is that it will display the text-content from Google’s cache. Nevertheless, if you don’t add “&strip=1” to the URL, your browser will pull live JavaScript, images, and other content from the live site (if it’s still up). This becomes extremely important for your OPSEC (Operational Security) when you are researching malware sites, hate groups, nation-state content, and organized crime as you do not want them to know they are being researched.
The below-animated GIF illustrates this on a test site Micah created for this purpose. It shows:
- Visit the website of interest: http://cached.sec487.info/
- Searching for that site on Google
- Use Google Cache to retrieve the site and now, have a look at the yellow image on the right
- Use the “text only” Google Cache content by using their link
- Adding “&strip=1” to the URL to pull up the same Google Cache-only content
- Use Developer Tools to see network calls your browser makes by using the Google Cache-only content (it only grabs content from Google’s site)
- Then try the same, but this time don’t add the “&strip=1” from the URL (see how it pulls JavaScript and an image from the target domain appears, alarming the group you’re researching).

Web Archives
Archive.org (with over 345 billion pages archived) and Archive.today (make sure to search your URL in the dark grey box. Using the red box will archive your page instead of searching the archive) are two websites which archive a lot of the internet web pages. Go check them out if you’re not familiar with them! By the way, Archive.today is the same as archive.is but since there is a party that has filed a complaint against the usage of the Icelandic domain extension, it is possible that this URL might stop working in the near future.
Also interesting: check if you can find EXIF metadata in old images shown on the website. This might give you some nice new research opportunities.
Similar websites or (sub)domain names
There are some websites that can help you find similar websites to the one you’re researching. This might not result in finding the exact website you’re looking at, but maybe they’ve copied the layout from another website, or perhaps they’ve continued under a new domain name. Websites like Alexa, Similarweb, Similarsitesearch or Similarsites (and there are probably lots more) let you search for similar sites.
If there is a chance that the website of interest might be running more domain names (e.g. with typos in there), you might want to check out those as well. There are websites which can help you create a list of common domain name typos for the domain name you’re interested in (like this one). But there is also a pretty cool tool you could use, called DNStwist. DNStwist will look at possible typos of your domain name and will also give you the WhoIs-information if the website is still up. Nevertheless, this does requir some command line skills in order to use.
If you prefer to use web-based and not command line tools, check out dnstwister.report. It does the same thing as DNStwist with the only difference that whenever you enter a domain name, it runs DNStwist in the background. While this set-up is very fast, you nevertheless lose some of your anonymity because you ask a third party to run DNStwist on your target domain.
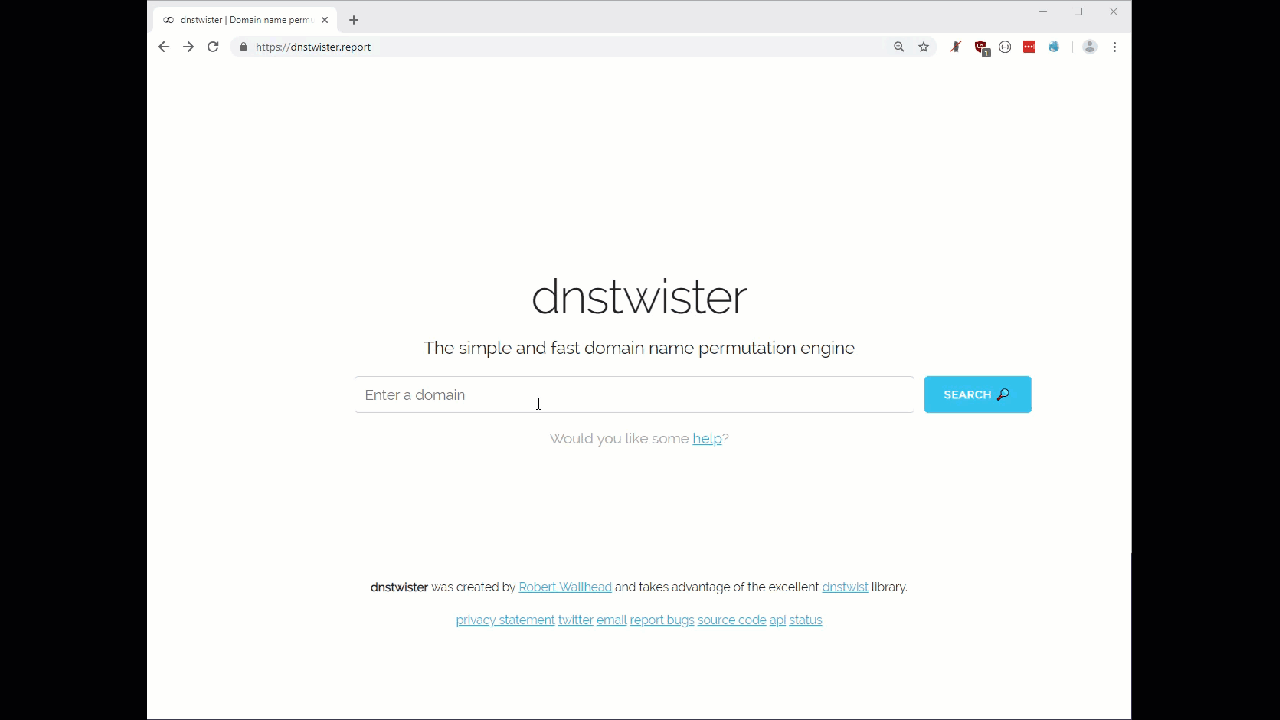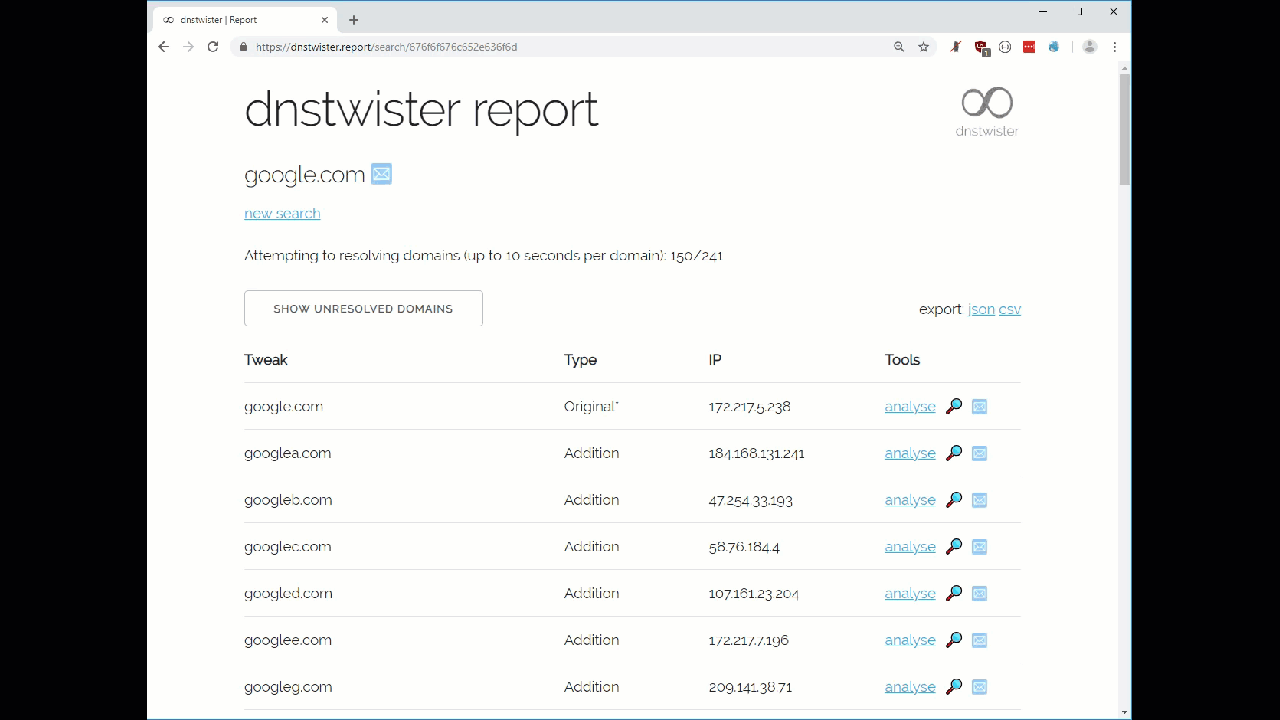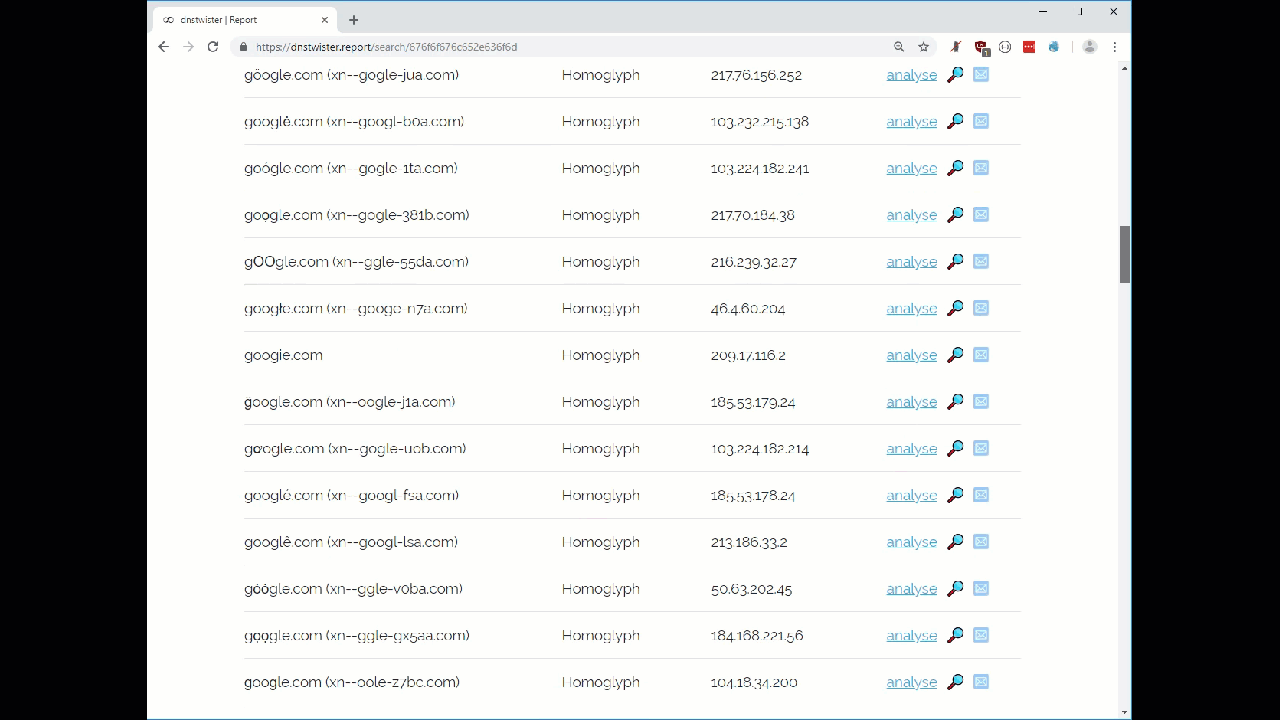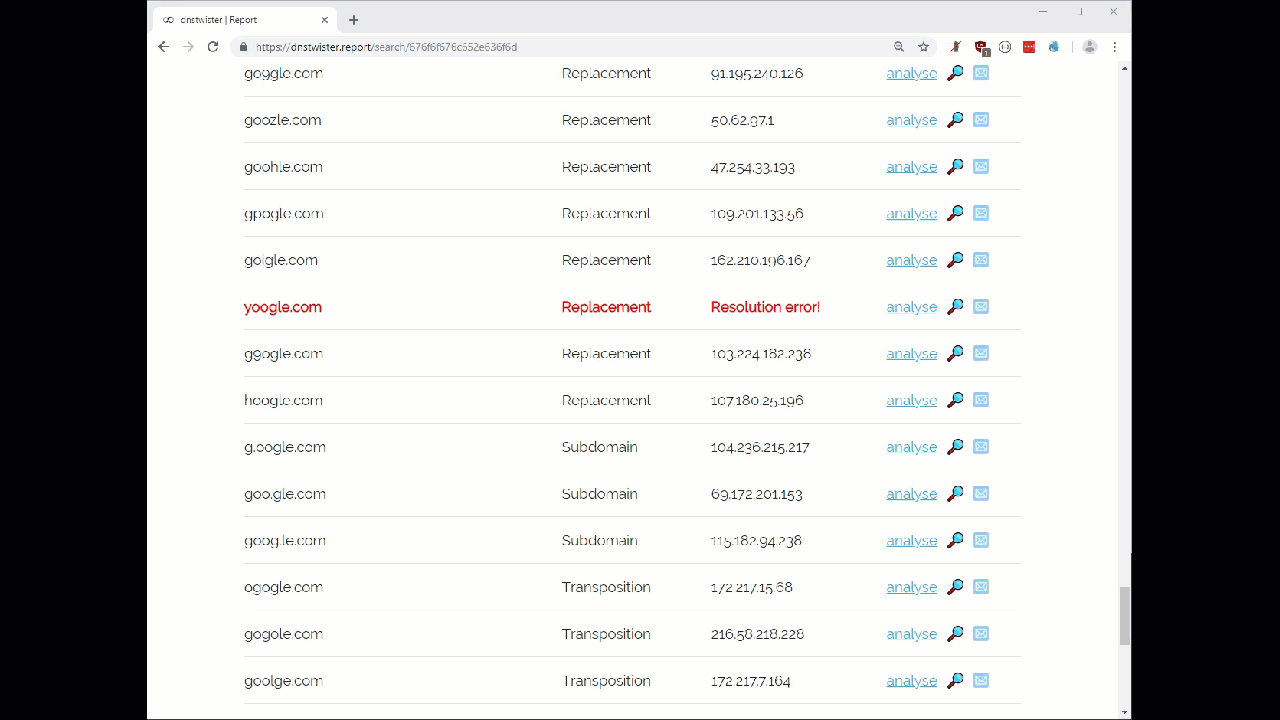
We ran the dnstwister.report site search on the Google.com domain in the graphic below to show the variety of domains that it can find.
And don’t forget subdomains! Sometimes a website might seem empty, but the subdomains could still be filled with lots of interesting stuff. Pentest-tools.com (has a search limit) and Findsubdomains.com (the good stuff is behind a login) will let you search for subdomains.
Add-ons
There are also a couple of add-ons which you can use in your browser to help you look into web archives. ResurrectPages (FireFox) and Go Back in Time (Chrome) are two pretty good ones. Whenever you land on a website which gives you the 404 error, they’ll give you suggestions in which online web archive site you could take a look at to see if your website might be archived there.
Certificates
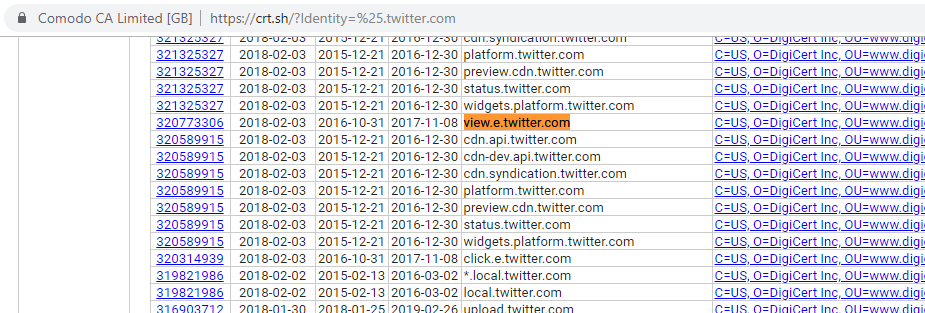
Another source of information is inside the certificate transparency logs that can be found on several sites. When you are interested in older (sub)domains, for instance, one can have a look at these reports via a site like crt.sh to find old, non-existing sub-domains to pivot on. As an example, one can have a look at all the certificates in the transparency report that contains ‘twitter.com’ and while going over the results old and defunct sub-domains are showing up in the history.
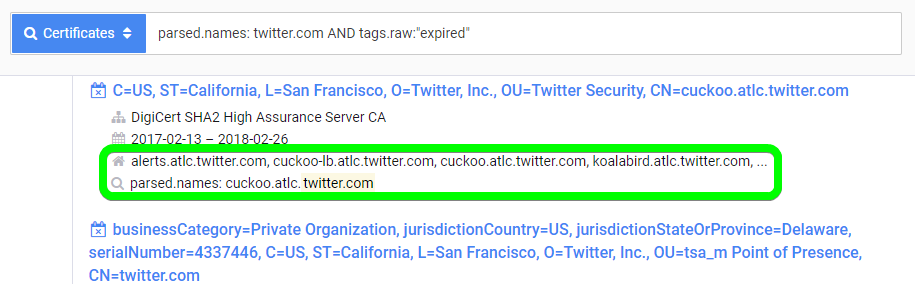
Another way of finding expired certificates and maybe even a hidden sub-domain is by using Censys.io to query their scan results. To have a look at the expired Twitter certificates that have been scanned, we can query Censys the following way:
parsed.names: twitter.com AND tags.raw:"expired"
After running this query and going over a few lines, we see another example of a sub-domain that is not valid anymore:
By opening the certificate itself in crt.sh or in Censys, we get even more information inside, usually directing you to even more sub-domains and sometimes more information about the environment it was used for.
The social media website/post I’m researching has been deleted
If you’re lucky enough to have some information, anything from a username, user ID or an ID of a post, this will help a lot when searching for that content.
Google Dorks
There are numerous ways to create Google “dorks”. Google dorks are just advanced searches that are performed on the Google search engine. If this is your first time trying, you might find some help here (from page 32). If you’re familiar with this, you might want to check out this crazy list with over 4500 dorks to get some inspiration.
When using these dorks take a look at the information you’ve got so far; if you have a userID, try to search for something like inurl:userID (or username) Maybe the ID or name has been used on a different website.
Or if you also know what platform they’ve used, try searching for NameOfPlatform “userID” (or “username”).
And there are a lot of other options too, so give it a shot!
When someone has changed their username (and therefore it looks like the content is deleted) it’s very handy to search by user ID. This is a unique number, given by the platform you’re using. If someone changes their username, they won’t be able to change the user ID. This works quite well for Instagram; because there are so many websites displaying Instagram’s content, you might be lucky to find information there.
Checking their username
When someone picks a username, a lot of them prefer to use that same username on other platforms too. Websites like Namechk, Namecheckr and Usersearch will let you check if a username is in use on a various range of platforms. You might be able to track down another profile of the same user. And if you’re lucky; they might have auto-forwarded certain posts to that platform.
Social media sites gone dark
Google just recently announced that Google+ (their social network) will be shut down in the beginning of April 2019. This will mean that their platform will no longer be searchable. But this is were the awesome team of Archive.org steps in, because they are working on a project in order to archive a much as possible from Google+.
They have done brilliant work in the past archiving other platforms that have gone dark(ish). MySpace (very popular social network before Facebook), although it still exists, has been archived pretty well. For example, the MySpace profile of Dutch DJ Hardwell has multiple entries in Archive.org. Hyves (very popular in the Netherlands before Facebook), now a gaming platform, also has multiple entries for DJ Hardwell.
If you’re wondering if this works for any other social media sites that are still up and running; it depends per platform.
If we keep looking at DJ Hardwell, his Facebook-page is indexed quite a lot on Archive.org, but it doesn’t show the actual content of the page. But his Twitter-page is archive quite well and so does his Instagram page. So it might be worth a shot to take a look at Archive.org to see if they have archived anything of the platform you’re interested in.
If there is a specific post that has been deleted, it might be a little harder to retrieve the information. Sometimes Google Cache and Archive come up with results. If they don’t, your best chance is to search for people who might have spoken about the post and might have saved screenshots. Or, when in law enforcement, you could see if the platform could deliver the content to you via a subpoena.
The Tor-site I’m researching has been deleted
Although a large part of the internet is being archived quite well, this is not the same for the Darkweb. But, there are a couple of interesting things to take a look at.
Search engines on the clear web
There are a couple of projects, like onion.link (when placing ‘.link’ behind a Tor website, this sometimes already shows you a copy of the site), that try to make to Darkweb searchable via a search engine on the clear web using the Tor2Web proxy software.
When searching for the full onion-URL in Google, Bing or Duckduckgo, this might result in websites links that provide you with a copy of that page.
And if you’re lucky, those clear web search engines might have a cached version available.
Darkweb databases
There are a lot of websites that keep track of anything that is happening on the Darkweb. Some of them keep charts of the post popular Darkweb sites and post screenshots of the specific pages. Those websites might have made a screenshot of the deleted content or you could check if someone archived/cached those websites like Darkwebnews, you might be able to find what you are looking for.
Also, websites like Reddit or Dreadditevelidot.onion, via Tor, have information about all kinds of Darkweb pages. Maybe someone has already made a post about the site of your interest and might have included a screenshot.
Hunchly Darkweb report
Or try the free Hunchly Daily Darkweb report issued by Hunchly. Every day you will receive a link to an Excel spreadsheet, which helps you identify new hidden services. But be careful, it’s not filtered so you might run into illegal content. This might help you determine how old an onion-link is. Although this might not show any screenshots, it might give you some clue on what was on that website.
Taking precautions
If you’re afraid that during your research content will be deleted by the owner or the platform; there are some precautions you could take.
Archive
If you’re not in the position to afford yourself a Hunchly license, you could always use Archive.org (they have an addon for Chrome and FireFox) or Archive.is (drag the button at the top to your bookmarklets) to archive the things that you are doing. The downside is that the information you archive will be made publicly available for other users. But at least you know that your data won’t be lost.
Taking Screenshots
If you’re afraid that stuff might get deleted, you can always take a screenshot. There are numerous add-ons, apps and other software for this purpose.
Browser extensions
The Chrome Extension SingleFile gives you the option to save the tab you are viewing as an mhtml file for later offline viewing or for taking a screenshot
The Chrome Extension Scroll++ does a similar thing and Scroll++ is also available as an Firefox Addon
Use Hunchly
When doing online research, having Hunchly (paid) to keep track of your investigations is almost something you can’t go without. It will keep track of everything you’re researching, saves it, allows you to search through it and much more. And its creator, Justin Seitz, writes blogs and gives (free!) webinars on how to use Hunchly in it most effective way.
Wrap-up
When doing online investigations, things will change or disappear. The prepared OSINT researcher will be more successful if they understand the sites and tools available, to help archive and retrieve data from internet and Darkweb sources.
Blog written by: Technisette, Micah Hoffman, Dutch OSINT Guy and Sector035.
P.S. Liked this posted? Support us via Patreon from just $1 a month!